在上一篇文章 AI 驅動的 Podcast 摘要系統(1) 中,我分享了如何運用 AI 技術打造一個解決 Podcast 摘要生成挑戰的計畫。隨著 Podcast 節目數量爆炸性成長,挑選出值得一聽的內容變得越來越困難。雖然我目前使用的訂閱工具 Podwise 表現不錯,但對於重度聽眾來說,標準方案的額度仍然不夠。因此,我決定設計並開發一套自動生成 Podcast 摘要的系統,透過語音轉文字、內容分析與摘要生成的流程,來提升效率並降低成本。
這套系統的核心目標,是讓使用者能夠快速掌握 Podcast 節目的重點,從而提升整體的聆聽體驗。今天,我終於邁出了實作的第一步。然而,過程中也遇到了一些技術上的挑戰,特別是在取得 Podcast 音檔並將其提供給 Whisper AI 進行語音轉文字處理方面。
一開始,我的構想是先將 Podcast 的音檔下載下來,接著上傳到支援 S3 的服務,再將公開的 S3 URL 提供給線上的 Whisper AI 進行轉錄。為此,我快速測試了兩套自動化流程平台:n8n 與 Dify.AI。雖然 Dify.AI 專注於 AI 流程設計,但在處理 S3 操作時顯得有些繁瑣,需要直接呼叫 Web API。相較之下,n8n 提供了現成的 S3 模組,讓整個操作過程更加簡便,因此我選擇了 n8n 來實現自動化流程。
我的初步設想是,使用者可以透過 HTTPie 或 Postman 等工具上傳檔案,然後 n8n 將檔案上傳到 S3,設為公開,並取得公開的 S3 URL,接著提供給 Whisper API 進行轉錄。這樣一來,我便能獲取 Podcast 節目的轉錄文本。整個流程看似美好,我也迅速在 DigitalOcean 上建立了一組 Spaces Object Storage,並在 n8n 很快地串好了整個流程,簡單來說就是一組 Webhook 串接 S3 檔案上傳,如下圖所示:

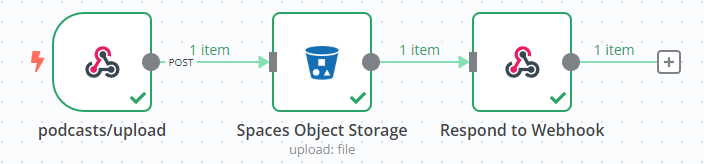
然而,當我準備測試這一流程時,才驚覺自己忽略了一個關鍵點:Podcast 的背後技術其實是 RSS,而 RSS 本身已經提供了節目音頻檔案公開訪問的 URL。因此,實際上並不需要花費大量時間下載音頻檔案,再經由 n8n 上傳到 S3。這個步驟無疑是「多此一舉」,完全畫蛇添足。
換句話說,今天的努力全部白費了。我本來只需編寫一個簡單的腳本,提取 RSS XML 中指定節目的音頻檔案 URL,即可直接進行轉錄,並利用 LLM 來生成摘要。這次的經歷讓我明白,有時候看似複雜的流程,其實可以簡化許多。
基於今天的學習,我決定暫時放下繁瑣的流程,專注於撰寫這篇文章,檢討自己的錯誤,並記錄今天遇到的問題。明天週末,我將花時間順過整個流程,確保它能以最小可行產品(MVP)的方式順利運作。
今天的探索雖然遇到了挫折,但也為未來的開發提供了寶貴的經驗。期待在接下來的日子裡,能夠逐步完善這套系統,為廣大 Podcast 愛好者帶來更便捷的聆聽體驗。
今天就先分享到這裡,感謝閱讀!


 iThome鐵人賽
iThome鐵人賽